BigQuery Uploader
The BiqQuery Uploader provides automated export of data to BigQuery, Google’s enterprise data warehouse.
Prerequisites
Uploading to BigQuery requires that you have a Google Cloud account with BigQuery enabled.
Upload scripts require authentication either through a Google Service Account or Google OAuth.
Google Service Account
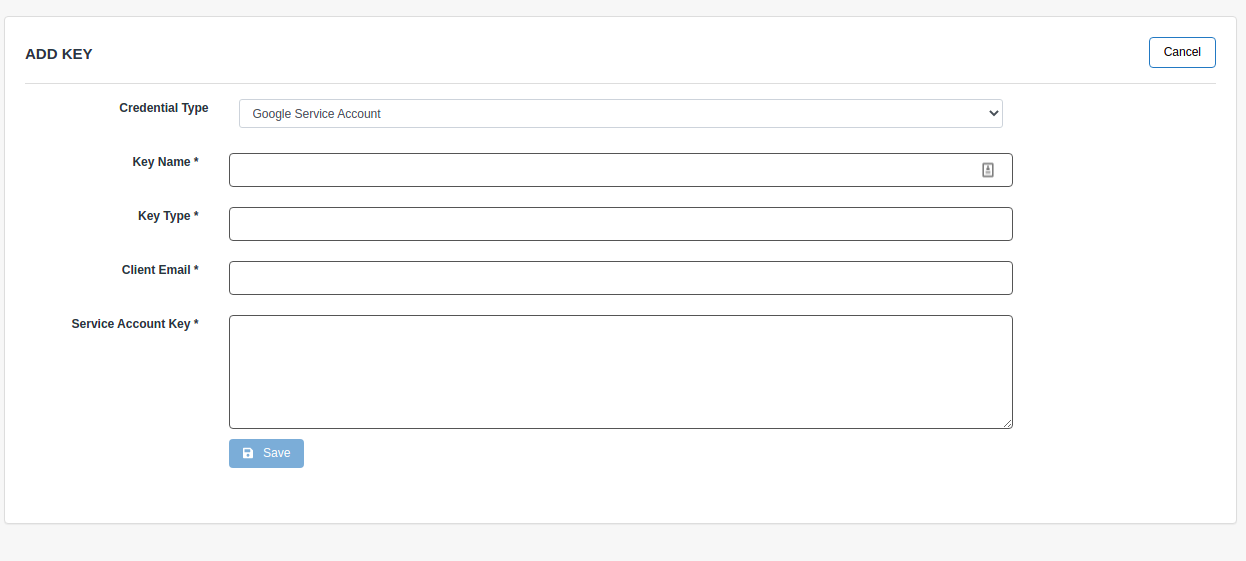
To authenticate via a Google Service Account add a Key with the Credential Type Google Service Account
Service accounts differ from user accounts in several key ways.
- Client Email
- Email address associated with the Service Account
- Key Name
- Value set here will be used in your Switchboard Script.
- Key Type
- Corresponds to the format of the Service Account Key. Typically the value is
json - Service Account Key
- Entire text of the key pair provided when a Service Account is generated
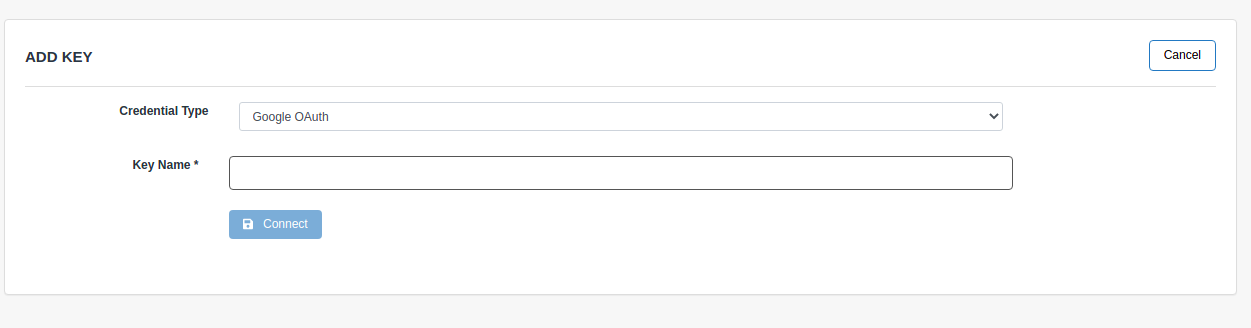
Google OAuth
To authenticate via Oauth you must add a Key with the Credential Type Google OAuth, enter a Key Name (used in the Switchboard Script below) and perform the Oauth flow by clicking the button labeled Connect.
Incremental Exports
Incremental exports are pushed to BigQuery whenever the download tied to this configuration is set to run, which can be specified in terms of hours or days.
Parameters
- dataset string
- required
- The identifier for the dataset within a BigQuery project into which data will be exported.
- test_dataset string
- :optional
- The dataset into which data will be exported for test runs.
- format string
- optional
- The data format to use when inserting into the dataset. By default this will be
parquetwhich is the most efficient way to upload but does not handle certain fields (such as date fields). Typically this does not need to be set and the compiler will warn you if this parameter needs to be modified. - Possible values include
avrocsvjsonparquet - primary_download_name string
- required
- The name of source of the data that was downloaded. This is required when the designated table name includes a ‘_YYYYMMDD’ naming convention
- project string
- required
- The identifier for the BigQuery project into which data will be exported.
- table string
- required
- The table in the dataset into which data will be exported. You may use a date naming convention to ensure the table name create is unique by date, i.e.
my_table_YYYYMMDD. Date formats require a primary source name, corresponds to the associated download - test_table string
- optional
- The table in the dataset into which data will be exported for test runs.
- truncate boolean
- optional
- specifies if the target table schema should be overwritten or not
Switchboard Script Syntax
upload t to {
type: "bigquery:load";
key: "my_bigquery_key";
project: "my-project";
dataset: "my-dataset";
table: "my_table_YYYYMMDD"; \\Date formats require a primary download name, corresponds to the associated download
primary_download_name: "t_raw";
truncate: true; \\ specifies if the target table schema should be overwritten or not
};
Full exports, Rollups and Aggregates
Full exports rebuild a table every time it runs and leverages bigquery:query within an import section.
This method is also used as a means to rollup, or aggregate, other tables into a single table and requires access to source tables containing the desired data to be joined.
Parameters
- dataset string
- required
- The identifier for the dataset within a BigQuery project into which data will be exported.
- project string
- required
- The identifier for the BigQuery project into which data will be exported.
- query string
- required
- A query to insert into the project specified by the
projectparameter
Switchboard Script Syntax
import my_full_biqquery_report from {
type: "bigquery:query";
key: "my_bigquery_key";
period_hours: 1;
project: "my-project";
query: "
CREATE OR REPLACE TABLE
`my-project.my-dataset.my_table_name`
as
SELECT
field1 as Field_1,
Date as Date,
COUNT(*) as c
FROM
`my-project.my-first-dataset.tableset1_*`
GROUP BY 1,2
UNION ALL
SELECT
filed1 as Field_1
date(date) as Date,
COUNT(*) as c
FROM
`my-project.my-second-dataset.tableset2_*`
GROUP BY 1,2
;
";
} using {
*
};